上次制作了输入股票代码,显示股票行情、历史数据、股评词云图的网页,但是,想要判断一只股票的投资价值仅看它自己的历史走势是不够的,还要与其他个股尤其是同行业个股进行比较。当然,行业轮动时选对行业是投资成功的第一步,那么如何在对的行业里优中选优?亦或在错的行业中避免错上加错?因此,有必要进行不同行业特征,以及同行业中不同个股之间的比较。
炒股软件虽然提供了各行业股票行情,但是缺少个性化指标的分析,所以把各行业的股票信息分别爬取下来,以便后续分析。
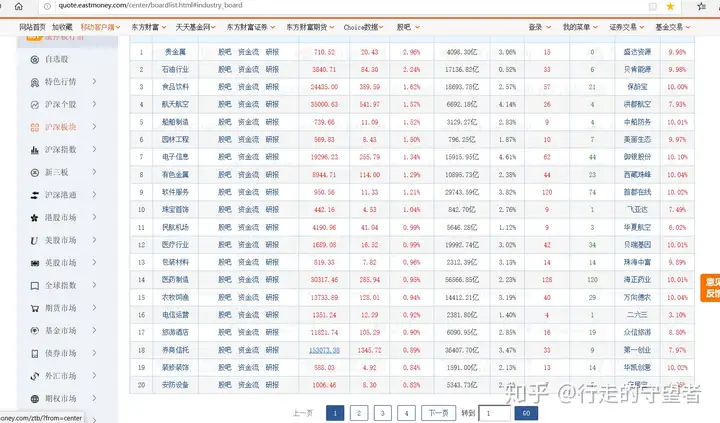
首先,打开东方财富网行情中心网页,可以看到所有行业共分4页,每页有20个行业。
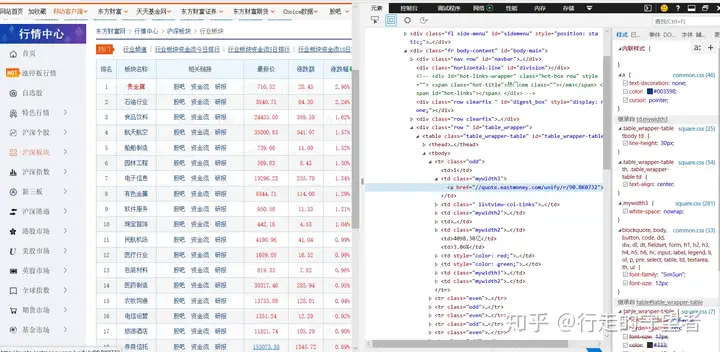
我们需要获取的是各个行业的详情页,即点击行业名称后跳转到该行业个股列表的详情数据。通过该网页前端源代码可以看到行业名称元素对应于一个网址,标签为href,这就是我们首先要点击进入的网址。定义函数get_url()获取这一网址,即各行业股票列表网址,并存储到字典url_dic中。
def get_url(): #获取各行业股票列表网址
url_dic = {}
browser=webdriver.Chrome(D:/chromedriver)
browser.get("http://quote.eastmoney.com/center/boardlist.html#industry_board")
time.sleep(1)
for i in range(1,5):
inputpage = browser.find_element_by_css_selector(.paginate_input)
inputpage.clear()
inputpage.send_keys(str(i))
inputclick = browser.find_element_by_css_selector(.paginte_go)
inputclick.click()
time.sleep(1)
hangye = browser.find_element_by_css_selector(table#table_wrapper-table>tbody)
tr_contents = hangye.find_elements_by_tag_name(tr)
for tr in tr_contents:
td = tr.find_elements_by_css_selector(td:nth-child(2))
for tdd in td:
hre = tdd.find_elements_by_tag_name(a)
# print(tdd.text)
for h in hre:
href = h.get_attribute(href)
# print(href)
url_dic[tdd.text] = href
# print(url_dic)
browser.close()
return url_dic
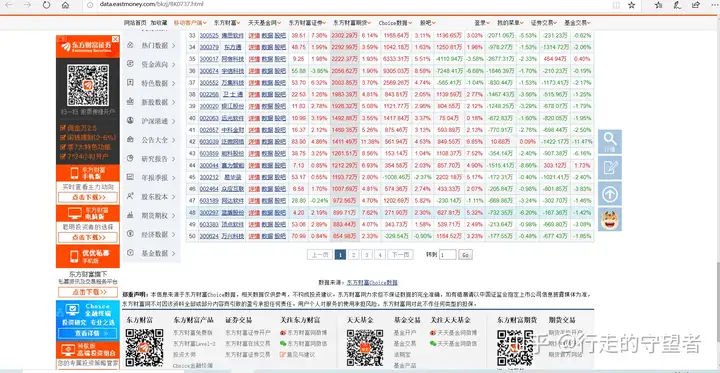
然后,点击某个行业(如“贵金属”),可以进入该行业详情页。将详情页下拉,可以看到下图所示的个股信息。但是这里的个股是不全的,需要点击“更多”获取该行业全部信息。
实际上,不难发现行业详情页的网址url和点击“更多”后跳转到的该行业全部股票列表网址存在部分相同,股票列表网址可以表示为
http://data.eastmoney.com/bkzj/+url[-6:]+.html
因此不需要进行模拟点击“更多”的操作,只需获取各行业详情页网址就可以直接编辑股票列表详情页并直接跳转。
进入全部股票列表页面后,还有一个问题,就是不同行业个股数量不同,总页面数也不同。比如,贵金属行业个股一共只有15只,只有一页即可放下,而软件服务行业个股有200只,共有4页(如下图)。所以,需要用专门的函数get_total_page(url)获取不同行业的股票页数。
这里有个坑,当总页数超过5页时,需要加入下面代码中的elif 判断语句,将全部页面加载出来后,再载计算总页数,否则会将总页数误认为只有5页。
def get_total_page(url): #获取某行业股票总页数
# browser=webdriver.Chrome(D:/chromedriver)
# browser.get(url)
# time.sleep(1)
inputpage = browser.find_element_by_css_selector(#PageCont)
# print(inputpage.text)
pa = re.findall(r\d+,inputpage.text)
print(pa)
if len(pa)==0:
# browser.close()
return 1
elif len(pa)==5:
nextclick = browser.find_element_by_css_selector(.next)
nextclick.click()
pa1 = re.findall(r\d+,inputpage.text)
return len(pa1)
else:
return len(pa)
下面定义获取每页股票信息的函数get_perpage_stock()
def get_perpage_stock(): #获取每页股票具体数据
# browser=webdriver.Chrome(D:/chromedriver)
# browser.get(url)
time.sleep(1)
element = browser.find_element_by_css_selector(#dt_1)
tr_contents = element.find_elements_by_tag_name(tr)
dat = []
for tr in tr_contents:
lis = []
for td in tr.find_elements_by_tag_name(td):
lis.append(td.text)
dat.append(lis)
return dat
有了上面两个函数,即可定义获取各行业全部股票数据的函数get_all_stock(),将各行业全部股票保存到字典 all_data
def get_all_stock():
for i,url in enumerate(dic.values()):
<全部代码关注微信公众号“朋友不发圈”获取>
return all_data
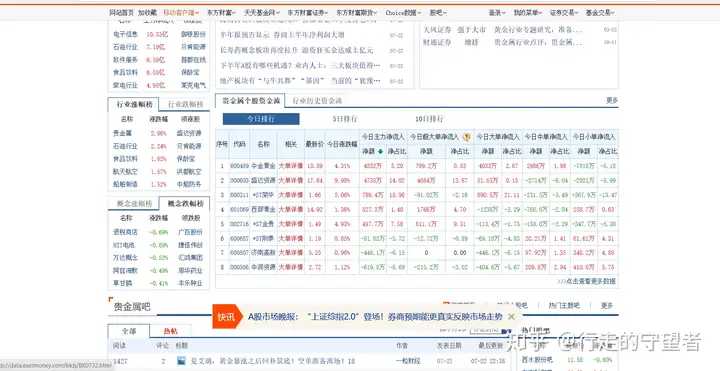
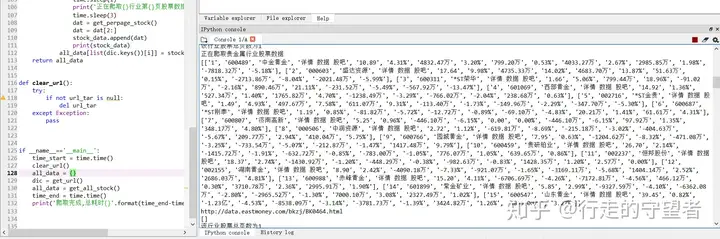
爬取过程如下图,
全部代码可关注微信公众号“朋友不发圈”获取(经测试无误,可直接运行),整个程序耗时924.52秒。