今天小编打算补充一下上一篇上市公司历史新闻数据分析(一)的部分内容,以及进一步阐述如何利用SVM和RandomForest做文本分类及效果对比。
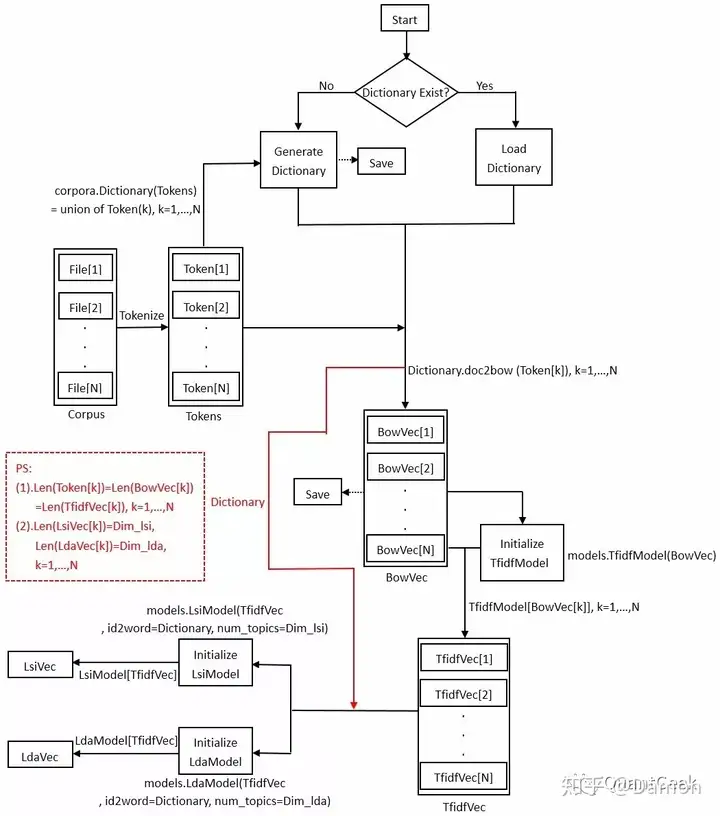
上一篇文章有提到用LDA主题模型做文本特征抽取,其实LDA主要是将“Document x Word”矩阵分解为“Document x Topic”矩阵和“Topic x Word”矩阵。通俗的说,LDA是为了说明某一系列的Words放在一起构成的Document很有可能在描述某一类Topic。下图显示了在实验中,将文本集转为lsi向量或lda向量的大致流程:
这里顺便说一下word2vec和doc2vec,两者都可以做特征抽取,但实验效果都没有LDA好,因此也就不描述实验。word2vec也叫word embeddings,就是根据词语与上下文词语的关系(相关情况),将已分词的文本进行训练,得到每个词的向量表示,即词向量(稠密向量,distributed representation),并且其中相近意义的词语将被映射到向量空间中相近的位置。主要有以下几点应用:(1)计算词语间的相似度,比如同样在城市主题下,衡量“北京”更接近“上海”还是“广州”;(2)计算词语的类比关系,比如“King”+“Woman”-“man”近似于“Queen”;(3)计算文本间的相似度。word2vec有两种训练算法,一个是CBOW模型,一个是skip-gram模型,详细解释可参考链接<1>。doc2vec又叫做paragraph2vec或者sentenceembeddings,是一种非监督式算法,可以获得句子/段落/文档的向量表达,是word2vec的拓展,详细解释可参考链接<2>。
在进行文本特征选择后,接下来就是文本表示,也就是把非结构化的文本转为计算机可以处理的结构化数据形式。在Gensim的官方教程(参考链接<3>)中有提到如何将Gensim类型数据转为Numpy和Scipy类型数据,转换的目的自然是为了适应更多机器学习库。在模型上,我选择了scikit-learn的SVM和RandomForest做对比。下面是一部分简约代码展示如何用GridSearchCV做参数优化:
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.externals import joblib
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
scores = [precision] #[precision,recall]
tuned_parameters_svm = {kernel: [rbf], gamma: [10, 20, 50, 100, 150, 200], \
C: [10, 15, 20, 30, 50, 100]}
tuned_parameters_rdf = {"n_estimators": [10, 20, 50, 80, 100], "criterion": ["gini", "entropy"], \
"min_samples_leaf": [2, 4, 6, 10, 20]}
for score in scores:
if not os.path.exists(./svm.pkl): #或./randomforest.pkl
clf = GridSearchCV(svm.SVC(), tuned_parameters_svm, cv=5, scoring=%s_weighted % score) # 构造这个GridSearch的分类器,5-fold
# clf = GridSearchCV(RandomForestClassifier(random_state=14), tuned_parameters_rdf, cv=5, scoring=%s_weighted % score) # 构造这个GridSearch的分类器,5-fold
clf.fit(train_X, train_Y) # 只在训练集上面做k-fold,然后返回最优的模型参数
joblib.dump(clf, ./svm.pkl) #或./randomforest.pkl
else:
clf = joblib.load(./svm.pkl)
print(clf.best_params_) # 输出最优的模型参数
# for params, mean_score, scores in clf.grid_scores_:
# print("%0.3f (+/-%0.03f) for %r" % (mean_score, scores.std() * 2, params))
train_pred = clf.predict(train_X)
test_pred = clf.predict(test_X) # 在测试集上测试最优的模型的泛化能力.
print(classification_report(test_Y, test_pred))
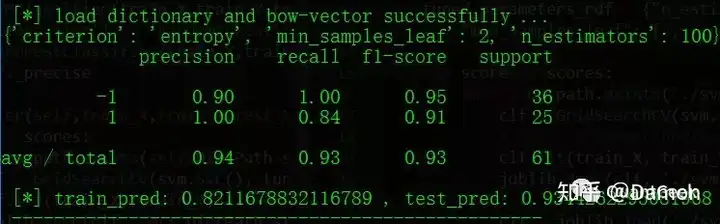
其中,scores是优化目标,可以按照准确率(precision)或者召回率(recall),当然还有别的;tuned_parameters_svm(tuned_parameters_rdf)表示选择的参数以及参数优化范围;训练好的模型最好还是用joblib给保存起来;最后用classification_report打印结果,如下图:
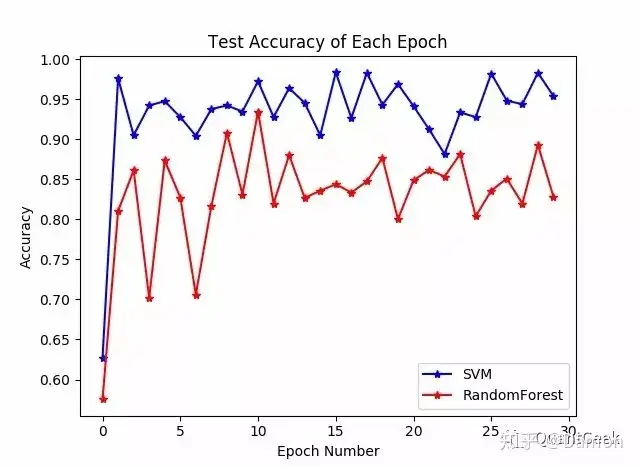
依然用山西焦化(600740)作为测试股票。首先从所收集的新闻数据中抽取与600740相关的新闻存到新的数据,并且依据这些数据生成600740的新闻字典以及bow向量,然后用LDA抽取主题模型向量,并保存。最后设置30个Epoch,来对比SVM和RandomForest在测试集的分类效果,如下图:
可见SVM在实验表现优于RandomForest。
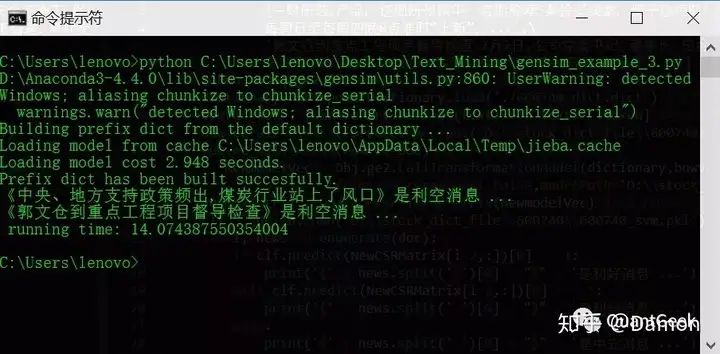
模型训练好了,当然得测试一下实际效果。由于新闻数据的收集只是到最近的2月3日,所以用2月3日之后的关于山西焦化的新闻数据进行测试。这里选了新浪财经在2月6日的一篇新闻(网址是参考链接<5>),标题是《中央、地方支持政策频出 煤炭行业站上了风口》,和金融界在2月5日的一篇新闻(网址是参考链接<6>),标题是《[山西焦化]郭文仓到终点工程项目督导检查》,下面是一段简约代码和输出结果:
Obj = TextMining(IP="localhost",PORT=27017)
doc = [中央、地方支持政策频出,煤炭行业站上了风口 券商研报浩如烟海,投资线索眼花缭乱,第一财经推出\
《一财研选》产品,挖掘研报精华,每期梳理5条投资线索,便于您短时间内获取有价值的信息。专业团队\
每周日至每周四晚8点准时“上新”,...,\
郭文仓到重点工程项目督导检查 2月2日,公司党委书记、董事长、总经理郭文仓,公司董事,股份公司副\
总经理、总工程师、郭毅民,股份公司副总经理张国富、柴高贵 ...]
token = Obj.ge2.jieba_tokenize(doc) #分词
dictionary = corpora.Dictionary.load(./600740_dict.dict) #加载历史文档字典
bowvec_doc = [dictionary.doc2bow(text) for text in token] #生成新文档的bow向量
bowvec_all = list(corpora.MmCorpus(D:\\stock_dict_file\\600740\\600740_bowvec.mm)) #加载历史文档bow向量
bowvec_all.extend(bowvec_doc) #更新历史文档bow向量
_, NewmodelVec = Obj.ge2.CallTransformationModel(dictionary,bowvec_all,modelType=lda,\
tfDim=200,renewModel=False,modelPath=D:\\stock_dict_file\\600740\\) #生成新的lda向量
NewCSRMatrix = Obj.ConvertToCSRMatrix(NewmodelVec) #将新的lda向量转为scipy类型的稀疏矩阵
clf = joblib.load(D:\\stock_dict_file\\600740\\600740_svm.pkl) #加载训练好的svm模型进行分类预测
for i, news in enumerate(doc):
if clf.predict(NewCSRMatrix[i-2,:])[0] == 1:
print(《 + news.split( )[0] + "》" + 是利好消息 ...)
elif clf.predict(NewCSRMatrix[i-2,:])[0] == -1:
print(《 + news.split( )[0] + "》" + 是利空消息 ...)
else:
print(《 + news.split( )[0] + "》" + 是中立消息 ...)
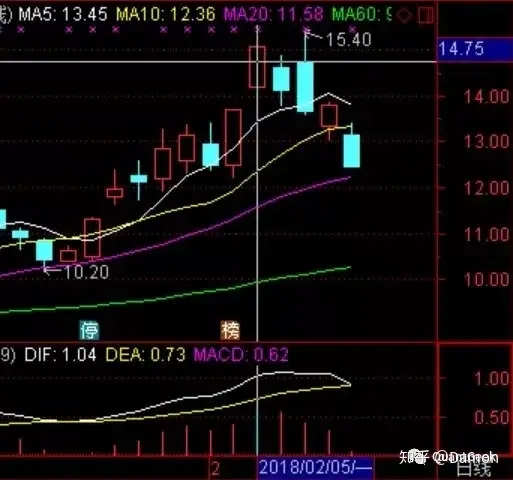
下面是山西焦化(600740)最近几天的股票价格,可见2月5日之后股票价格下跌,当然也不排除这几天的下跌多数是由系统性风险造成。但总的来说,这次的研究还是蛮具有实战价值。
参考链接:
<1> http://blog.csdn.net/u014595019/article/details/51884529
<2> https://www.cnblogs.com/maybe2030/p/5427148.html
<3> https://radimrehurek.com/gensim/tut1.html#compatibility-with-numpy-and- scipy
<4> http://blog.csdn.net/lixiaowang_327/article/details/53434744
<5> http://finance.sina.com.cn/stock/hyyj/2018-02-04/doc- ifyreyvz9053830.shtml
<6> http://stock.jrj.com.cn/2018/02/05000024071826.shtml